
Story Splitting: Cuando el Tamaño se Convierte en Riesgo (Artículo 6 de 7)
Serie Gemba: AI Mercadona User Story Framework — Descomposición de historias grandes en incrementos seguros y valiosos

Este es el sexto artículo de una serie de 7 sobre el AI Mercadona User Story Framework. Después de recorrer el Quality Guard, Research, JTBD to Stories y Quality Coach, llegamos al módulo desarrollado por Eduardo Ferro (@eferro): Story Splitting. https://www.eferro.net/
La paradoja del trabajo de software: El riesgo crece más rápido que el tamaño
Hace poco más de una década, mientras trabajaba en equipos de entrega continua, Eduardo Ferro se dio cuenta de algo que parecía desafiar la lógica. Si tomabas una tarea que normalmente tardaba una semana y la hacías el doble de grande, el riesgo asociado no se duplicaba. Se multiplicaba por cuatro. A veces, incluso por diez.
Este descubrimiento no era teórico. Lo vio una y otra vez en retros, en despliegues fallidos, en historias que se arrastraban sprint tras sprint. El patrón era consistente: cuanto más grande era una historia, más cosas podían salir mal. No de manera lineal. De manera exponencial.
La razón es simple pero profunda. Una historia pequeña —una que toma tres días o menos— es un “experimento sobrevivible”. Si algo falla, el equipo puede revertir rápidamente, aprender, y seguir adelante. El costo del error es manejable.
Pero una historia de dos semanas o más es diferente. Si falla, has invertido semanas en el trabajo. Otros equipos están esperando. Revertir no es una opción elegante; es un desastre. Los equipos no revierten. Aceptan un resultado mediocre. Dedican más tiempo a arreglarlo. La historia se estira. La incertidumbre crece. El riesgo se expande.
Esta es la razón por la que Eduardo Ferro diseñó el módulo de Story Splitting que hemos usado en el AI Mercadona User Story Framework: no como un ejercicio académico de descomposición, sino como una defensa práctica contra el riesgo exponencial. Su objetivo es simple pero ambicioso: detectar automáticamente las historias que son demasiado grandes para ser seguras y descomponerlas en incrementos que sean, cada uno, independientemente valiosos, desplegables por sí solos, y completables en tres días o menos.
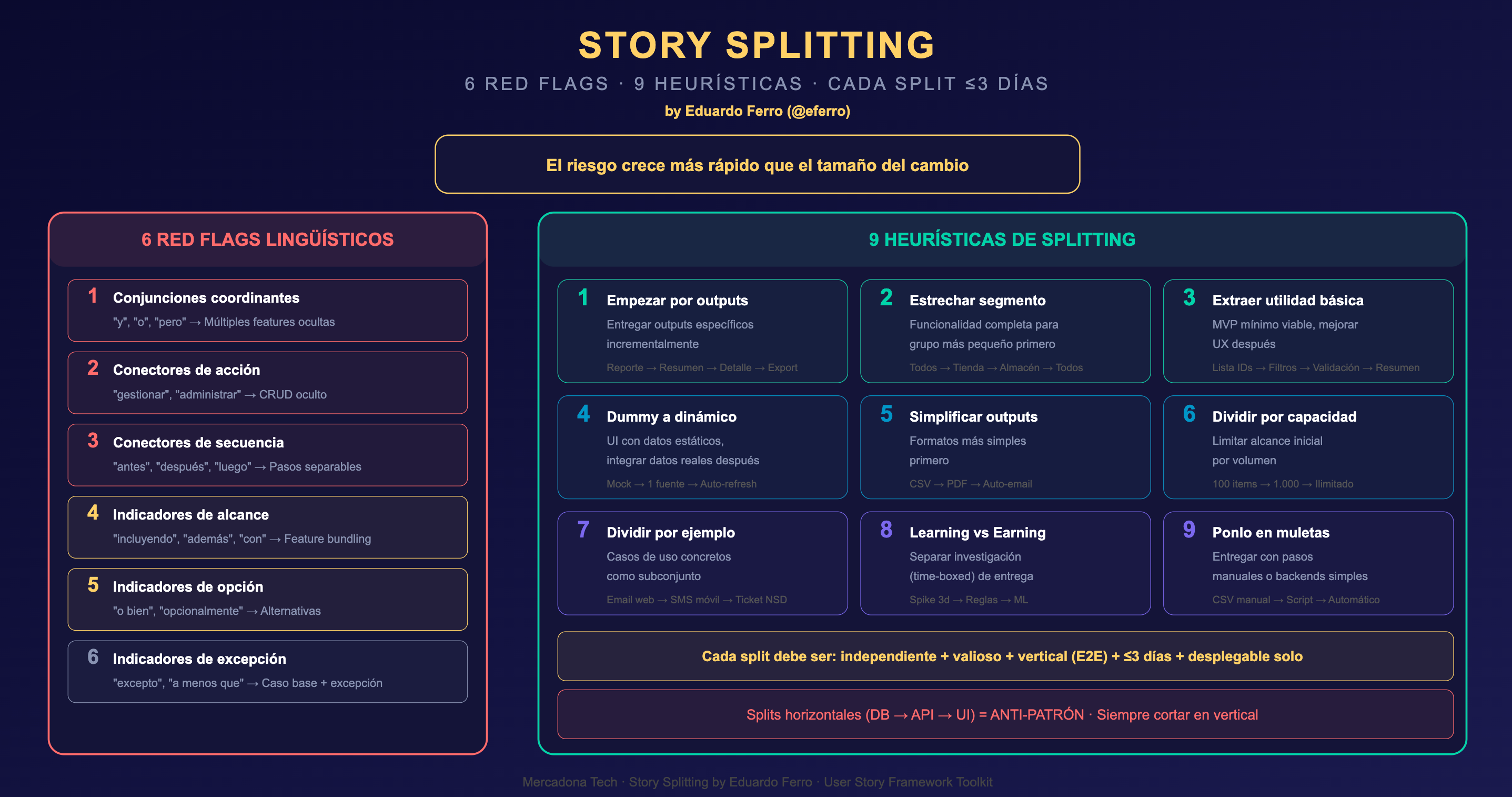
El primer paso: Detectar cuando el peligro está oculto en el lenguaje
Eduardo reconoció que el tamaño excesivo de una historia casi siempre se anuncia a sí mismo. No a través del número de líneas, sino a través del lenguaje. Las historias que son demasiado grandes tienden a usar palabras específicas que revelan que esconden múltiples historias dentro de una sola.
Identificó seis categorías de indicadores lingüísticos que actúan como banderas rojas.
Primera categoría: las conjunciones coordinantes. Cuando una historia dice “Los usuarios pueden subir y descargar archivos”, está ocultando dos historias completamente separadas. Subir es un flujo completamente diferente al de descargar. Tienen diferentes interfaces, diferentes casos de error, diferentes criterios de éxito.
Segunda categoría: los conectores de acción. Palabras como “gestionar”, “administrar”, “procesar”, “manejar”. Estos verbos casi siempre esconden operaciones CRUD completas. “Gestionar usuarios” es crear, leer, actualizar y eliminar usuarios. Eso son potencialmente cuatro historias.
Tercera categoría: los conectores de secuencia. Palabras como “antes”, “después”, “luego”, “entonces”. Revelan historias que agrupan pasos separables que podrían entregarse de forma independiente.
Cuarta categoría: los indicadores de alcance. Palabras como “incluyendo”, “además”, “también”. Cada palabra de este tipo es un síntoma de que alguien añadió una característica más a lo que ya era una historia completa.Quinta categoría: los indicadores de opcionalidad. Palabras como “o bien”, “opcionalmente”, “alternativamente”. Cuando una historia presenta múltiples caminos opcionales, está escondiendo historias que deberían desarrollarse por separado.
Sexta categoría: los indicadores de excepción. Palabras como “excepto”, “a menos que”, “sin embargo”, “en caso de”. La mejor práctica es desarrollar y desplegar el caso base primero —el 80% del trabajo—, y después, en historias posteriores, añadir las excepciones y los bordes. Las excepciones son donde la mayoría de los bugs se esconden.
El genio de Eduardo en el diseño del módulo fue automatizar esto. El modulo de Eduardo que usamos en el AI Mercadona User Story Framework escanea la descripción de la historia buscando exactamente estas palabras y estructuras lingüísticas. Cuando las encuentra, levanta una bandera. No para rechazar la historia, sino para alertar al equipo de que aquí hay complejidad oculta que merece atención consciente.
El segundo paso: Transformar la detección en acción
Detectar que una historia es demasiado grande es solo el primer paso. El verdadero valor está en saber cómo dividirla. Eduardo Ferro, basándose en años de experiencia con equipos en entrega continua, destiló nueve heurísticas específicas de splitting que transforman las historias monolíticas en historias pequeñas, seguras, y todavía valiosas.
Heurística 1: Comenzar por los outputs. Los outputs son entidades discretas. Si estás construyendo un reporte, puedes entregar primero la versión más simple: el resumen en texto plano. Después, los detalles. Después, la exportación a CSV. Cada uno puede validarse, desplegarse y usarse de forma independiente.
Heurística 2: Estrechar el segmento. Entregar funcionalidad completa para el grupo más pequeño posible. Si estás construyendo una característica para “todos los usuarios”, pregúntate: ¿Puedo entregarla primero solo para los empleados de tienda? Esta heurística reduce dramáticamente la complejidad.
Heurística 3: Extraer la utilidad básica. El MVP es lo mínimo. Lo bello puede venir después. Si estás construyendo cancelación en lotes, la primera historia es subir una lista de IDs. La segunda añade filtros. La tercera añade validación. Cada una entrega valor y cada una es pequeña.
Heurística 4: De lo dummy a lo dinámico. Los datos estáticos primero, después los datos reales. Si estás construyendo un dashboard, la primera historia muestra datos hardcodeados. La segunda conecta a una fuente real. La tercera añade auto-refresh. Divide el problema arquitectónico del problema de datos.
Heurística 5: Simplificar los outputs. Formatos más simples primero. Si estás generando un reporte, la primera historia genera CSV. La segunda genera PDF. La tercera lo auto-envía por email. La complejidad crece de forma predecible.
Heurística 6: Dividir por capacidad. Limitar el alcance por volumen. La primera historia procesa 100 artículos. La segunda 1,000. La tercera es ilimitada. Cada versión es completamente útil por sí misma.
Heurística 7: Dividir por ejemplo. Para cambios grandes, usar casos de uso concretos. Si estás construyendo comunicación post-cancelación, la primera historia es email a usuarios web. La segunda es SMS a usuarios móviles. La tercera es tickets en soporte. Cada una es un flujo completo y valioso de punta a punta.
Heurística 8: Aprender vs Ganar. Separar la investigación de la entrega. Si estás construyendo un sistema de recomendaciones con machine learning, la primera historia es un spike de investigación: 3 días máximo, que responde una pregunta específica. La segunda es una versión simple basada en reglas. La tercera, quizás 3 sprints después, es el modelo de ML. La investigación y la entrega son diferentes tipos de trabajo. Mezclarlas casi siempre hace que ambas sean malas.
Heurística 9: Ponerla en muletas. Entregar con pasos manuales o backends más simples. Si estás sincronizando inventario, la primera historia es subir manualmente un CSV y procesar cambios. La segunda es un script semi-automático. La tercera es sincronización completa y automática. Cada una es una historia valiosa que el negocio puede usar.
Lo que Eduardo Ferro entendió es que estas heurísticas no son arbitrarias. Cada una separa una dimensión diferente de la complejidad. Cada una permite que un equipo entregue, valide, aprenda, y luego avance.
El concepto que todo lo une: El experimento sobrevivible
Hay un concepto central que recorre todas las heurísticas: el “experimento sobrevivible”.
Una historia pequeña —tres días o menos— es un experimento. Si descubre que no es el enfoque correcto, el equipo puede revertir rápidamente. El costo del aprendizaje es bajo. El experimento falló, pero fue barato.
Una historia grande —dos semanas o más— no es un experimento sobrevivible. Si falla, la inversión es demasiado grande. El equipo no puede revertir. Tiene que aceptar una solución mediocre. Esto es lo opuesto a la agilidad.
Cuando divides una historia grande en historias pequeñas, cada una de ellas se convierte en un experimento sobrevivible. El equipo puede validar supuestos de forma frecuente, obtener feedback frecuente, y ajustar el rumbo. La suma de las historias pequeñas no es solo más manejable. Es fundamentalmente más segura.
La regla que muchos olvidan: Siempre vertical, nunca horizontal
Hay una regla en el framework de Eduardo Ferro que es tan importante, y tan frecuentemente violada, que merece énfasis especial: las divisiones siempre deben ser verticales, nunca horizontales.
Una división horizontal sería separar la historia en capas técnicas: “Implementar el endpoint de API”, “Implementar la lógica de negocio”, “Implementar la interfaz de usuario”. Esto parece lógico desde la perspectiva técnica. Pero es una trampa. Porque ninguno de estos “trabajos” entrega valor por sí solo.
Si algo sale mal en la lógica de negocio, has comprometido también el trabajo del endpoint y la interfaz. Las “historias” horizontales no llegan nunca a done. Se agrupan de nuevo cuando llega el momento del release. Y estás de vuelta a una historia grande.
La manera correcta es vertical. La historia debe cruzar todas las capas de tecnología y entregar valor completo de punta a punta. “Los usuarios pueden crear un pedido con los datos básicos” cruza la interfaz, la API, la lógica de negocio, la base de datos. Y entrega valor.
El marco de validación: Criterios que no son negociables
Una vez que tienes una propuesta de split, el framework de Eduardo ofrece cuatro criterios que cada split propuesto debe cumplir. Si no los cumple, el split no es válido.
Primero, la historia debe ser independientemente valiosa. El usuario o el negocio pueden obtener valor de esta historia completada, sin necesitar las otras historias que se dividieron de la original.
Segundo, la historia debe ser desplegable sola. Si la completaste, puedes desplegarla a producción sin desplegar las otras historias.
Tercero, la historia debe ser completable en tres días o menos. Esta es la línea que dibuja Eduardo. Si toma más de eso, tiene riesgo exponencial.
Cuarto, la historia debe entregar valor de punta a punta. No es un “componente de la infraestructura”. Es una capacidad completa que el usuario puede ejercer.
La tabla de decisión: Automatizar lo que puede ser automatizado
Una de las características más útiles del módulo es la tabla de decisión. Es una asignación explícita de indicadores lingüísticos a heurísticas de splitting.
Si encuentras “gestionar”, la tabla recomienda Heurística #1 (comenzar por outputs). Si encuentras “y”, sugiere dividir por conjunción. Si encuentras “para todos los usuarios”, recomienda Heurística #2 (estrechar el segmento).
Esto convierte lo que podría ser un ejercicio subjetivo en algo sistemático. Eduardo capturó la sabiduría que un experto en descomposición tendría y la empaquetó en reglas que cualquier equipo puede aplicar. La descomposición no es un arte. Requiere disciplina. Y eso es escalable.
En la práctica: Cómo cambia el trabajo
Sin el framework, un equipo recibe una historia como: “Gestionar usuarios del sistema, incluyendo creación, actualización y eliminación, además de reseteo de contraseñas, con soporte para roles y permisos, opcionalmente con autenticación de dos factores.” Es grande. Se estima en 21 puntos. Se estira a tres sprints. El usuario obtiene algo, pero no es exactamente lo que esperaba.
Con el framework de Story Splitting, la misma historia se convierte en:
Historia 1 (3 días): Los usuarios administradores pueden crear usuarios locales con nombre, email y contraseña inicial.
Historia 2 (2 días): Los usuarios administradores pueden editar el email y el nombre de usuarios existentes.
Historia 3 (2 días): Los usuarios administradores pueden eliminar usuarios.
Historia 4 (3 días): Los usuarios administradores pueden asignar roles (admin, editor, viewer). Permisos se aplican basándose en roles.
Historia 5 (3 días): Los usuarios pueden resetear sus propias contraseñas a través de un link enviado por email.
Historia 6 (spike de 3 días): Investigación de autenticación de dos factores.
Historia 7 (3 días, después del spike): Los usuarios pueden opcionalmente configurar 2FA con SMS.
7 historias pequeñas en lugar de 1 gigante. El equipo completa la primera en dos días. Obtiene feedback. Para el final de las dos primeras semanas, ha entregado cuatro historias completamente funcionales — el 70% del valor. Comparado con el escenario tradicional donde aún están lidiando con bugs de permisos, esto es un cambio radical.
Conclusiones: El cambio que cambia cómo pensamos sobre el trabajo
El módulo de Story Splitting del AI Mercadona User Story Framework, diseñado por Eduardo Ferro, representa algo más profundo que una técnica de descomposición. Representa un cambio en cómo pensamos sobre el riesgo en el desarrollo de software.
El riesgo no es una constante que aumenta linealmente con el tamaño. Aumenta exponencialmente. Una historia de tres días tiene un tipo de riesgo. Una historia de tres semanas tiene un tipo de riesgo completamente diferente. Es el riesgo de no poder revertir. De estar atrapado. De ser forzado a aceptar una solución mediocre.
Cuando divides historias grandes en pequeñas, no estás solo haciendo que sean más manejables. Estás transformando el tipo de riesgo que asumes. Cada pequeña historia es un experimento. El blast radius de cualquier error es pequeño.
El framework de Eduardo automatiza el proceso de identificar dónde el riesgo está oculto —en el lenguaje de las historias que escribimos—, y proporciona un conjunto sistemático de heurísticas para transformar esas historias en incrementos seguros y valiosos.
Hay una razón por la que Eduardo ha enfatizado la regla vertical vs horizontal tan fuertemente. Es porque es fácil fingir que estás siendo ágil mientras estás cometiendo el mismo error viejo: crear trabajo que no entrega valor a nadie hasta que está 100% completo. El framework te obliga a ser honesto. Cada historia debe entregar valor de verdad. Cada historia debe poder ser desplegada sola. Cada historia debe ser completable en tres días.
Cuando pones estas restricciones, algo interesante sucede. Los equipos comienzan a preguntarse: “¿Cuál es la pieza más pequeña que puedo hacer que todavía agregue valor?” En lugar de: “¿Cómo puedo hacer todo de una vez?”
Esta es la pregunta que cambia los equipos de buenos a grandes. Y es la pregunta que el Story Splitting de Eduardo te obliga a hacer.
Próximo Artículo (7 de 7): Story Builder — El módulo final del AI Mercadona User Story Framework que permite a los equipos construir historias desde cero, sin un DAPP como punto de partida, usando un diálogo estructurado que asegura que lo que crean es una historia bien formada desde el inicio.
Un tema muy menor. Creo que falta un salto de linea antes de Heurística 8.
Por cierto que no es que yo me inventase nada, esta todo inventado, pero si que con el paso del tiempo he ido encajando las piezas :)
Gracias por hacerte eco