
Qué es un token
La moneda en la que pagamos la era de la IA, explicada desde el algoritmo. Tres familias de tokenizadores, cómo se calculan y por qué cambian tu factura más de lo que parece.

Llevamos dos años pagando IA en una moneda que casi nadie entiende.
Cada llamada a un LLM se cobra en tokens. Tu plan de Claude tiene un límite de tokens. La ventana de contexto se mide en tokens. Las empresas comparan modelos por su precio por millón de tokens. Y a pesar de eso, si paro a diez profesionales del sector y les pido la definición exacta de un token, nueve me dan algo aproximado y uno me dice que “más o menos es una palabra”.
Pues Chorprecha!! No es una palabra!!.
Hace unos meses me obligué a entenderlo de verdad. No leyendo artículos: implementando el algoritmo desde cero en Python, byte a byte, sin librerías. El código está al final del artículo por si te apetece mirarlo después.
Hoy te cuento qué es un token, cómo se inventan, por qué un emoji cuesta cinco veces más que la palabra “el”, y qué decisiones de producto cambian cuando entiendes la unidad en la que pagas. Si trabajas con IA, esto es contabilidad básica de tu negocio.
Un token no es una palabra
La aproximación que más oirás —”un token es más o menos una palabra”— es útil para hacer una estimación rápida en una pizarra y desastrosa para casi todo lo demás. Veámoslo con tres palabras.
“Hola” es un token. Una palabra, un token. El mito sobrevive.
“Mercadona”, en cambio, se parte en tres trozos cuando la procesa el tokenizador de GPT-4: algo parecido a Merc, ad, ona. Tres tokens para una sola palabra. El mito empieza a romperse.
“Supermercado” se parte en dos: super y mercado. Dos tokens, dos sub-palabras que sí aparecen mucho en el corpus de entrenamiento y que el algoritmo ha decidido guardar como piezas reutilizables.
Y un emoji como 🛒 puede convertirse en cuatro o cinco tokens él solo, porque ni siquiera cabe en un byte: hay que codificarlo en UTF-8 y luego volver a juntarlo.
¿Por qué tanta variación? Porque un token no es una unidad lingüística. Es una unidad estadística. El tokenizador no sabe español, no sabe inglés y no sabe que “Mercadona” es una empresa: lo que sabe es que ciertos pedazos de texto aparecen mucho juntos en su corpus de entrenamiento, y los guarda como piezas. Lo que aparece menos, lo deja sin agrupar.
La regla útil para hacer cuentas rápidas, si trabajas con tokenizadores entrenados sobre todo en inglés (la mayoría de los grandes), es algo así:
Inglés: 1 token ≈ 0,75 palabras
Español: 1 token ≈ 0,5 palabras
Código fuente: 1 token ≈ 3-4 caracteres
Si solo te llevas una cosa de esta sección: cuando escribes en español, estás pagando casi el doble que un anglosajón por decir lo mismo. Y eso no es un accidente. Es una consecuencia directa de cómo se entrena el tokenizador, que es de lo que va la siguiente sección.
BPE: el dominante de la era GPT
El algoritmo más usado se llama BPE (Byte Pair Encoding). Es engañosamente simple y resuelve un problema concreto: cómo cubrir todo el texto del mundo —cualquier idioma, emojis, código, errores de teclado— con un vocabulario fijo y eficiente.
No puedes hacer un diccionario “a mano”. Tampoco puedes usar bytes sueltos (H, o, l, a son cuatro tokens para una sola palabra: ineficiente). BPE encuentra el punto medio: un vocabulario aprendido a partir de los datos.
Funciona en tres pasos. La versión esencial:
Paso 1 — Empezar por lo más básico. El vocabulario inicial son los 256 bytes posibles. Cualquier texto del universo se puede expresar como una secuencia de estos 256 elementos. Eso garantiza que nada queda fuera, ni los emojis ni los caracteres japoneses ni nada.
Paso 2 — Contar pares por frecuencia. Aquí “frecuencia” significa algo muy concreto: cuántas veces aparece cada par de tokens adyacentes en los documentos que forman el corpus de entrenamiento. Y ese corpus no es pequeño: hablamos de cientos de miles de libros, páginas web, repositorios de código, foros, conversaciones y artículos —en GPT-4 son varios billones de tokens en total—. El algoritmo recorre ese mar de texto y, para cada par adyacente posible, lleva un contador. Esa cuenta —y nada más— es lo que decide qué tokens nacen y cuáles no. No hay análisis sintáctico, no hay reglas, no hay diccionarios. Solo recuento de coapariciones.
Paso 3 — Fusionar el ganador y repetir. Coges el par más frecuente, lo declaras un nuevo token, le asignas un identificador nuevo (256, 257, etc.) y recorres todo el corpus reemplazándolo. Vuelves a contar pares —ahora los nuevos tokens también participan— y repites. Cada vuelta, el vocabulario crece en uno.
Un ejemplo con la cuenta de la vieja
Para ver qué significa exactamente esa “frecuencia”, reduzcamos el corpus a algo que se pueda contar a mano. Imagina que tu corpus de entrenamiento es minúsculo: solo cuatro palabras, cada una repetida un número conocido de veces en los documentos.
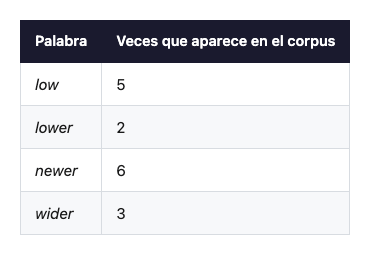
Empezamos descomponiendo cada palabra en sus letras y contamos cuántas veces aparece cada par adyacente en todo el corpus, multiplicando por la frecuencia de su palabra:
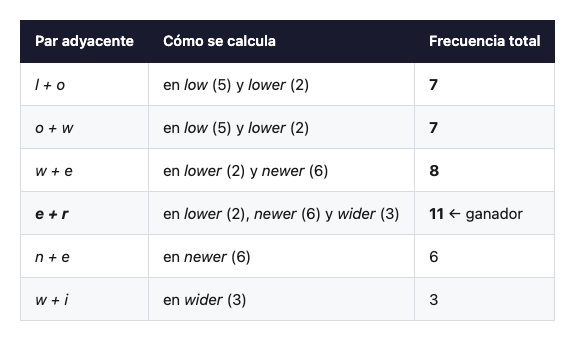
El par más frecuente es e + r con 11 apariciones. Lo fusionamos: nace un nuevo token, er, y todo el corpus se reescribe con él:
lower ahora es l, o, w, er
newer ahora es n, e, w, er
wider ahora es w, i, d, er
Volvemos a contar. Esta vez ganará w + er, que aparece en lower y newer un total de 8 veces, y nacerá el token wer. Y así sucesivamente. Cada iteración añade un token al vocabulario y comprime un poco más la representación del corpus.
Si dejas correr el algoritmo 50.000 veces, tienes un vocabulario de 50.000 tokens. La mayoría serán sub-palabras frecuentes (ción, mente, super, inter), algunas serán palabras enteras muy comunes (de, que, the), y otras serán piezas raras que el algoritmo decidió guardar porque aparecían lo bastante.
Lo interesante: no hay reglas lingüísticas en ningún sitio. El algoritmo no sabe que ción es un sufijo ni que super es un prefijo. Lo descubre solo porque aparece mucho en los datos. Es el equivalente, en mi mundo de Information Retrieval clásico, a descubrir bigramas frecuentes en un corpus —”New York”, “machine learning”— sin que nadie te diga que son entidades.
Quién usa BPE hoy. GPT-4 y GPT-4o (con tiktoken), Claude (variante propia de BPE), Mistral, Qwen, Llama 3 y prácticamente todos los modelos generativos de uso masivo en producción. Si trabajas con un LLM comercial moderno, casi seguro estás pagando en tokens BPE.
Unigram + Viterbi: el algoritmo que trabaja al revés
Si BPE construye el vocabulario de abajo arriba —empezando con bytes sueltos y fusionándolos—, Unigram hace lo contrario: empieza con un vocabulario gigante de candidatos y va podando los menos útiles hasta dejar solo los que de verdad valen la pena.
Lo curioso es que aquí “frecuencia” deja de ser un simple recuento. En Unigram, cada candidato a sub-palabra tiene asociada una probabilidad estimada a partir del corpus: la probabilidad de que esa sub-palabra aparezca en un documento elegido al azar. Y la probabilidad de una palabra entera —por ejemplo, lowest— se calcula multiplicando las probabilidades de los trozos en los que se segmenta.
El algoritmo funciona así, simplificado en cuatro pasos:
Paso 1 — Construir un vocabulario inicial enorme. Se extraen del corpus todas las sub-palabras candidatas hasta cierta longitud: las que aparecen al menos N veces se incluyen. Es habitual empezar con un vocabulario diez veces más grande del que queremos al final.
Paso 2 — Estimar la probabilidad de cada candidato. Con un algoritmo iterativo llamado EM (Expectation-Maximization), ajustas las probabilidades de todas las sub-palabras del vocabulario de forma que el corpus completo se explique con la máxima verosimilitud posible.
Paso 3 — Encontrar la mejor segmentación con Viterbi. Dada una palabra y un vocabulario con probabilidades, ¿cuál es la mejor forma de partirla? Aquí entra el algoritmo de Viterbi, un método de programación dinámica que encuentra el camino óptimo entre todas las segmentaciones posibles sin tener que probarlas una por una. Por cierto: es el mismo algoritmo que se usaba en los años ochenta y noventa para etiquetar gramaticalmente las palabras de una frase —POS tagging, de Part-of-Speech: marcar cada palabra como sustantivo, verbo, adjetivo, etc.— combinado con HMM (Hidden Markov Models, modelos probabilísticos de secuencias en los que los estados que generan las observaciones permanecen ocultos). Era el estado del arte del procesamiento del lenguaje natural antes de los transformers.
Paso 4 — Podar y repetir. Los candidatos cuya eliminación apenas afecta a la verosimilitud del corpus se descartan. Se vuelven a estimar las probabilidades, se vuelve a podar, y así hasta llegar al tamaño deseado de vocabulario.
Un ejemplo con la cuenta de la vieja
Imagina que hemos entrenado un Unigram y la palabra lowest puede segmentarse de varias formas. Cada candidato tiene una probabilidad estimada a partir del corpus:
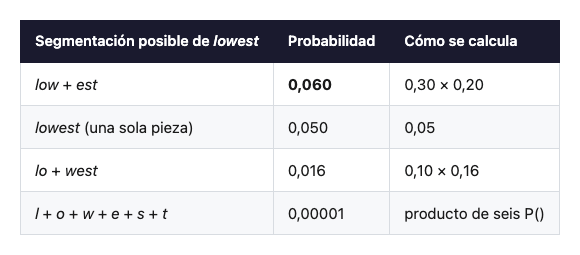
Viterbi recorre estas opciones eficientemente y se queda con la de mayor probabilidad: low + est. Esa es la segmentación que el modelo “verá”.
Mientras BPE fusiona por frecuencia bruta, Unigram elige por verosimilitud. Eso le permite manejar mejor casos ambiguos y, sobre todo, idiomas con morfología compleja —japonés, coreano, finés— donde la segmentación no es obvia.
Una nota histórica que conviene recordar. Tendemos a pensar que todo lo que rodea a los LLMs es tecnología muy reciente, pero la mayoría de los ladrillos que sostienen esto llevan décadas inventados. El algoritmo de Viterbi lo publicó Andrew Viterbi en 1967 para decodificar señales de telecomunicaciones; lo trasladó al procesamiento de lenguaje natural toda una generación de investigadores en los años setenta y ochenta. Los HMM se formalizaron como modelo probabilístico a finales de los sesenta y dominaron el reconocimiento de voz y el etiquetado gramatical durante treinta años. El algoritmo EM —el que ajusta las probabilidades del vocabulario en Unigram— lo publicaron Dempster, Laird y Rubin en 1977 en uno de los papers más citados de la historia de la estadística. Incluso BPE como técnica de compresión es de 1994 (Phillip Gage), y solo se reutilizó para NLP en 2016 (Sennrich, Haddow y Birch). Cuando alguien te diga que la IA generativa es “magia nueva”, recuerda que detrás de cada token que pagas hay matemáticas con cincuenta años de historia.
Quién usa Unigram + Viterbi. T5 (Google), mBART, ALBERT, XLNet y, en general, muchísimos modelos entrenados con SentencePiece en modo Unigram. Es especialmente popular en modelos multilingües y en buena parte del ecosistema asiático.
WordPiece: BPE con un criterio más exigente
WordPiece es, esencialmente, BPE con una pequeña diferencia conceptual que cambia bastantes cosas en la práctica. Sigue construyendo el vocabulario de abajo arriba, fusionando pares iteración a iteración, pero el criterio para elegir el par ganador es distinto.
Mientras BPE elige siempre el par más frecuente, WordPiece elige el par que más mejora la probabilidad del corpus al fusionarse. La fórmula que usa en la práctica para puntuar cada par (A, B) es:
score(A, B) = freq(AB) / (freq(A) × freq(B))
Léelo despacio: el numerador es cuántas veces aparece el par junto en el corpus; el denominador es cuántas veces aparece cada pieza por separado, multiplicadas. El cociente premia los pares cuyos componentes casi siempre van juntos, aunque su frecuencia bruta no sea la más alta. Es, en espíritu, una versión simplificada del pointwise mutual information (PMI) que llevamos décadas usando en lingüística computacional.
El mismo ejemplo, otro ganador
Volvamos al corpus de antes (low: 5, lower: 2, newer: 6, wider: 3). Comparemos dos pares:

BPE habría elegido e + r. WordPiece elige i + d, porque la fusión es más “informativa”: cuando ves i en el corpus, prácticamente siempre viene d justo detrás, así que tratarlos como un solo token reduce mucho más la ambigüedad.
En la práctica, los vocabularios resultantes de BPE y WordPiece se parecen mucho, pero WordPiece tiende a capturar mejor las unidades con asociación fuerte —prefijos, sufijos, raíces poco frecuentes pero cohesionadas— y peor las simples coapariciones de piezas individualmente comunes.
Una nota histórica más. WordPiece se publicó originalmente en 2012 por Schuster y Nakajima (Google), para mejorar el reconocimiento de voz en japonés y coreano. Solo en 2018 lo redescubrió el público general cuando Google lo usó para entrenar BERT.
Quién usa WordPiece hoy. BERT y toda su familia de encoders: DistilBERT, ELECTRA, MobileBERT, los primeros ALBERT. Es la elección dominante en modelos de búsqueda semántica, clasificación y information retrieval moderno. En LLMs generativos de uso masivo, en cambio, ha quedado relegado a un papel secundario.
La factura: cómo el tokenizer cambia lo que pagas
Aquí es donde toda esta arqueología algorítmica aterriza en tu cuenta corriente. Resumamos lo que llevamos:
El tokenizer decide cuántos tokens caben en cada texto.
Esa decisión depende del corpus con el que se entrenó.
Tú pagas por token.
Esas tres líneas son toda la teoría que necesitas para entender la factura. Lo que falta son los matices, que son los que se cobran.
Por qué un emoji cuesta cinco tokens y “el” cuesta uno
“el” aparece varios cientos de millones de veces en cualquier corpus en español. Cualquier tokenizador decente lo guarda como un token único y lo encuentra al primer intento. Un emoji como 🛒, en cambio, aparece poquísimo en los corpus de entrenamiento (las páginas web técnicas, los libros y los repositorios de código no rebosan emojis). El tokenizador no le asigna un token propio. Resultado: hay que codificarlo en UTF-8, que son cuatro bytes, y cada byte se trata como un token aparte. Un solo emoji puede convertirse en cuatro o cinco tokens él solo.
La misma lógica se aplica a tu jerga técnica, a nombres propios poco habituales o a esa expresión regional que no salía en los foros del corpus.
Por qué pagas más por escribir en español
Aquí entra el sesgo de corpus. La mayoría de los grandes modelos —GPT, Claude, Llama— se entrenan con un corpus en el que el inglés domina muy ampliamente. Los pares de bytes en inglés son más frecuentes y, por tanto, los pares en inglés tienen sus propios tokens “comprimidos”. Los pares en español, no tanto. La consecuencia práctica: una frase en español tiene entre un 30% y un 80% más tokens que la misma frase en inglés, dependiendo del modelo.
“House” es un token. “Casa” suelen ser dos: ca + sa. Multiplica eso por cada mensaje, cada usuario, cada día.
La cifra real (mayo 2026)
Para que la factura aterrice, una foto del mercado a precios de hoy, por millón de tokens:
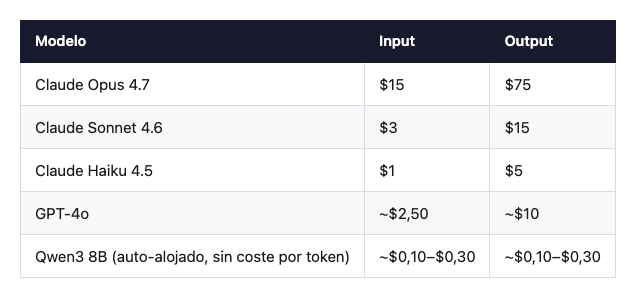
Parecen cifras pequeñas hasta que multiplicas por usuarios reales. Un asistente conversacional con un usuario activo medio consume con facilidad 50.000–200.000 tokens al día entre input y output. Saca la cuenta para 10.000 usuarios.
El multiplicador oculto
Y aquí está el detalle que más se escapa: si tu modelo es caro y su tokenizer es malo para tu idioma, no pagas el sobrecoste una vez, lo pagas dos veces. Pagas más caro por token, y pagas más tokens por cada mensaje. Es factor multiplicador, no sumatorio.
Un 30% más caro por token × 50% más tokens por mensaje = casi el doble de factura mensual para el mismo producto, comparado con un modelo equivalente con tokenizador bien afinado a tu idioma.
Esa es la razón por la que la decisión “qué LLM usamos” no se puede tomar solo mirando el ranking de calidad ni solo mirando el precio por token. Hay que mirar las dos cosas a la vez, y mirarlas en el idioma en el que tu producto se usa de verdad.
Lo que entender los tokens te permite hacer
Llegados aquí, sabes qué es un token, cómo nace, por qué unos cuestan más que otros y cómo todo eso se traduce en factura. La pregunta práctica es qué cambia en tu trabajo a partir de mañana. Cuatro cosas concretas, todas accionables.
Audita tu gasto en la unidad correcta. La métrica útil no es “cuántas peticiones hace mi producto al LLM al día”. Es cuántos tokens consume cada funcionalidad por usuario activo al día. Esa diferencia es la que separa los equipos que escalan IA en serio de los que se llevan sorpresas a final de mes. Si trabajas con un proveedor cerrado, instrumenta tu código para registrar tokens de input y de output por endpoint, por feature y por usuario. Sin ese dato, no estás gestionando un producto IA: estás cruzando los dedos.
Elige el tokenizer cuando elijas el modelo. Si estás evaluando modelos open source, no mires solo el ranking ni la latencia. Mete tu propio texto representativo en el tokenizer de cada candidato y mide cuántos tokens te salen. Un modelo “barato” con un tokenizer malo para tu idioma puede ser, en la práctica, más caro que un modelo “caro” con un tokenizer bien afinado.
Decide con criterio entre las cuatro palancas. Hablamos en el [artículo anterior](https://www.gemba.es/p/por-que-tu-proximo-llm-en-produccion) de las cuatro herramientas para mejorar un LLM: prompt engineering, RAG, tools y fine-tuning con LoRA. Cada una tiene un coste muy distinto medido en tokens. Un buen prompt te ahorra tokens en cada llamada; RAG mete más tokens en cada llamada; tools puede tener cualquier perfil; LoRA paga el coste una vez en entrenamiento y ninguno en inferencia. Entender el coste en tokens de cada palanca es lo que convierte la decisión “¿cuál uso?” en una decisión con número, no con intuición.
Optimiza el prompt cortando contexto barato. El último ejercicio: revisa los prompts de sistema que más se ejecutan en tu producto y mira cuántos tokens consume el contexto fijo. Casi siempre hay un 10%-30% que se puede recortar sin pérdida de calidad. En productos con tráfico real, ese 20% se traduce directamente en miles de euros al mes.
Los tokens son la unidad de tu producto. Tratar la unidad como una caja negra es trabajar a ciegas. Tratarla con criterio es lo que separa los productos IA que escalan de los que se hunden en su propia factura.
Dos toolkits abiertos para que lo experimentes
Para que esto no se quede en lectura, he preparado dos repositorios públicos, ambos con licencia MIT, pensados para roles distintos.
📦 gemba-tokenizers-from-scratch — Los tres algoritmos implementados desde cero en Python, sin librerías externas.
Es la versión código de este artículo. BPE, Unigram con Viterbi y WordPiece, cada uno en un fichero corto, comentado, con ejemplos paso a paso y comparativas sobre el mismo texto. No es código de producción: es código para entender. Pensado para que lo abras, lo ejecutes, lo modifiques y veas en directo cómo cada algoritmo toma decisiones distintas con el mismo corpus. Incluye un playbook para Claude Code que carga el repo y permite hacer preguntas tipo “tokeniza esta frase con los tres algoritmos y compara”.
🧮 gemba-token-cost-calculator — Calculadora de coste real en varios modelos y varios idiomas.
Esto es lo opuesto: producción, no didáctica. Usa los tokenizadores reales —tiktoken para OpenAI, transformers de HuggingFace para Llama 3, Qwen, Mistral, T5 y BERT, y la API oficial de Anthropic para Claude— y los combina con una tabla de precios actualizable. Le metes un texto representativo de tu producto (o un fichero), eliges los modelos y los idiomas que quieres comparar, y te devuelve cuánto te cobraría cada combinación. También se invoca como skill de Claude Code: /calcular-tokens texto.md gpt-4o,claude-opus,qwen3-8b. Pensada para tomar decisiones de presupuesto con número, no con intuición.
Uno para entender, el otro para decidir. Los enlaces directos están al final, en el cierre.
Para terminar
Llevamos dos años pagando IA en una moneda que casi nadie se ha parado a mirar de cerca. Hoy ya la has mirado. Sabes que un token no es una palabra, que se inventa contando frecuencias sobre un corpus, que hay tres familias —BPE, Unigram con Viterbi, WordPiece— y que cada una toma decisiones distintas con consecuencias muy concretas en tu factura. Sabes también que detrás de esa “magia nueva” hay matemáticas que algunos investigadores estaban escribiendo cuando aún no había internet.
La pregunta con la que te dejo es esta: ¿sabes cuántos tokens consume un usuario tuyo en un día normal? Si la respuesta es no, mañana es buen día para empezar a medirlo. Es la primera métrica que tienes que dominar para construir productos IA que escalen sin reventar la cuenta.
Hasta el lunes que viene.