
¿Por qué los LLMs olvidan?
La curva en U que pagamos cada día. Por qué Claude o ChatGPT recuerdan el principio y el final de tu contexto y se evaporan en el medio. La mecánica matemática del olvido, explicada desde dentro.

En 1962, Bennet Murdock publicó un experimento que cambió la psicología cognitiva.
Pidió a sus sujetos memorizar listas de cuarenta palabras y, después, recitarlas en cualquier orden. Recordaban las primeras (efecto de primacía). Recordaban las últimas (efecto de recencia). El medio se evaporaba.
Sesenta y cuatro años después, los LLMs hacen exactamente lo mismo. Solo que, en lugar de palabras, lo que se evapora son los tokens por los que estás pagando.
La curva es idéntica. La explicación no.
Cuando empecé a usar Claude y ChatGPT a diario, asumí que los olvidos eran un capricho del modelo o algo relacionado con su naturaleza no determinista. Le pasaba un contexto largo, le hacía una pregunta concreta sobre algo del medio, y a veces respondía bien y a veces no. Una lotería. Tardé en cogerlo. Lo cogí cuando dejé de leer papers y empecé a visualizar la atención capa por capa en un transformer pequeño. Ver el mapa cambia las cosas. El código, los demos y la reproducción con GPT-2 están [aquí](https://github.com/josemerca/gemba-attention-from-scratch).
Hoy te cuento por qué los LLMs olvidan, cuánto te está costando ese olvido, y qué puedes hacer para minimizarlo. Si trabajas con IA, esto es ergonomía básica del producto.
La memoria no es lo que parece
Cuando hablas con Claude o con ChatGPT, tienes la sensación cómoda y engañosa de estar conversando con algo que recuerda. Le dices una cosa, le dices otra, le pides que vuelva a la primera. La mayoría de las veces parece funcionar. Y eso es justo el problema.
Lo que llamamos “memoria” en un LLM no se parece en nada a la memoria humana. No hay un sitio donde el modelo “guarda” lo que le has dicho. No aprende mientras hablas con él. Sus pesos están congelados desde el día en que terminó de entrenarse, y no cambian ni un decimal durante toda la conversación. Lo que sí existe es una ventana de contexto: una secuencia finita de tokens que el modelo tiene delante cada vez que genera una respuesta. Y cuando llega tu siguiente mensaje, la ventana se reescribe entera con todo lo anterior más lo nuevo, y el modelo vuelve a procesarla desde cero.
Lo que llamamos memoria es, técnicamente, releer.
Cada conversación con Claude Opus 4.7 cabe en hasta un millón de tokens. GPT-4o trabaja en 128.000. Gemini 1.5 Pro estira hasta dos millones. Parecen cifras enormes, y lo son comparadas con los 2.048 tokens del GPT-3 original o los 4.096 con los que se lanzó ChatGPT, pero siguen siendo finitas. Cuando una conversación pasa de ese tope, los tokens más antiguos se descartan literalmente: el modelo deja de “verlos”. No los olvida en sentido figurado; desaparecen del input.
Dentro de la ventana, los tokens viven en una estructura de la que rara vez somos conscientes: el KV cache —caché de claves y valores, keys y values en inglés, las dos siglas detrás de las dos letras—. Es un buffer físico en memoria de GPU donde se almacenan, por cada token y por cada capa del modelo, esas dos matrices: una de claves y otra de valores. Piensa en la clave como la etiqueta del token —algo así como “yo soy un trozo de texto que habla de esto”— y en el valor como el contenido que ese token aporta cuando otro token decide mirarlo. Para Llama 3 70B con 100.000 tokens de contexto en precisión BF16 (dos bytes por número), el KV cache ocupa unos 30 GB de VRAM —la memoria interna de la GPU—, casi la mitad de una GPU H100 dedicada solo a recordar lo que ya le has dicho. Y eso gracias a Grouped-Query Attention (GQA), una técnica que comparte claves y valores entre varios cabezales de atención para abaratar el coste; sin GQA esos mismos 100k tokens ocuparían más de 150 GB. Es por eso que GQA es estándar de facto en casi todos los modelos abiertos modernos: Llama 3, Mistral, Qwen 2.5, Gemma. No es una metáfora ni una abstracción: es hardware. Cuando los proveedores te cobran por “input tokens”, parte de lo que estás pagando es ese hardware encendido durante el tiempo que tu contexto está cargado.
Y aun así, el KV cache no resuelve el problema. Resuelve el “cómo se almacena el contexto”, pero no el “cómo se mira”. Esa segunda parte —la atención— es donde nace el olvido. Y es donde se origina la factura que pagamos sin darnos cuenta.
El cuello de botella cuadrático
La operación matemática que define a un transformer no es la multiplicación de matrices grande ni el softmax exótico. Es una sola fórmula que mide cuánto le importa cada token a cada otro token:
Atención(Q, K, V) = softmax(Q · K^T / √d) · VDonde Q, K y V son las matrices de queries, keys y values que mencionamos en §1. Lo importante no es la fórmula. Lo importante es lo que hace por debajo: para cada token de la secuencia, compara su query con la key de todos los demás tokens y calcula un peso. Luego, usando esos pesos, mezcla los values de todos los demás tokens en una nueva representación.
Cada token mira a cada otro token. Cada uno. Sin excepciones.
Si tienes n tokens, eso son n × n comparaciones por capa, por cabezal de atención y por paso de generación. Y en un Llama 3.1 405B (126 capas × 128 cabezales), esa cifra se multiplica por unas dieciséis mil veces antes incluso de empezar a generar el siguiente token. Esa propiedad —que el coste crece con el cuadrado del contexto— se escribe en la jerga como O(n²), y es lo que en este artículo llamaré el cuello de botella cuadrático.
Veámoslo con una tabla. Lo que cuesta procesar un contexto de tamaño n, comparado con uno de mil tokens:
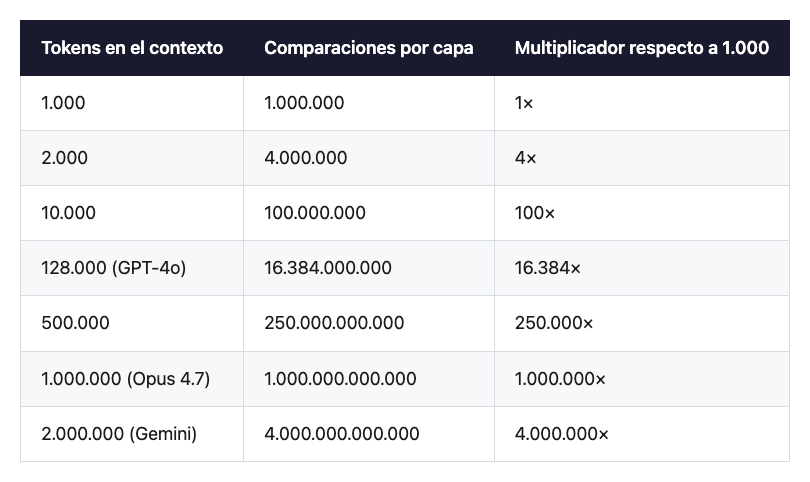
Si nunca habías visto los números así, deja que asienten un segundo: una conversación con Claude Opus 4.7 que llena la mitad de su ventana —medio millón de tokens— hace doscientas cincuenta mil veces más trabajo de atención que una conversación de mil tokens. No quinientas veces. Doscientas cincuenta mil. Y si llenas la ventana entera hasta el millón, un millón de veces más. Un billón europeo de comparaciones por capa de transformer.
Doblar el contexto no cuesta el doble. Cuesta cuatro veces más.
Aquí es donde aparece la consecuencia incómoda. Ese coste cuadrático tiene que pagarlo alguien. Los proveedores no lo pueden absorber indefinidamente, así que aparece en tres sitios distintos: en el precio por millón de tokens de input (que va subiendo con el tamaño de la ventana), en la latencia (modelos como Claude tardan más en arrancar cuando el contexto es muy largo), y —el más sutil de los tres— en cómo el modelo distribuye su atención dentro de la ventana.
Porque cuando una operación cuesta n², la forma más natural de abaratarla es no mirar a todos los tokens por igual. Y eso, aplicado mil veces durante el entrenamiento, deja una huella permanente en el modelo: aprende a atender preferentemente a unos sitios y a ignorar otros. La forma exacta de esa huella es lo que descubrió Liu en 2024. Y se parece sospechosamente a lo que descubrió Murdock en 1962.
Lost in the middle
En julio de 2023, Nelson Liu y un equipo de Stanford colgaron en arXiv un paper con un título poco humilde: Lost in the Middle: How Language Models Use Long Contexts. La versión revisada apareció en 2024 en TACL, una de las revistas de referencia del procesamiento del lenguaje natural. Es uno de esos papers que confirman, con números, una sospecha que todo el mundo en el sector tenía pero nadie había medido bien.
El experimento es elegante por lo simple. Cogieron diez modelos —GPT-3.5-Turbo en sus dos versiones, GPT-4 en un subconjunto, Claude-1.3 y Claude-1.3-100k, MPT-30B base e Instruct, LongChat-13B-16K, Flan-T5-XXL y Flan-UL2— y les pasaron contextos largos con una técnica que en la jerga se llama needle in a haystack —literalmente, “una aguja en un pajar”—: meter dentro de un texto enorme una “aguja” —un dato único, una clave, una respuesta a una pregunta concreta— y luego preguntar por esa aguja. El truco está en variar la posición. La aguja puede estar a la entrada del pajar, a un cuarto, en el centro, a tres cuartos o al fondo. Y medir cuántas veces el modelo la encuentra.
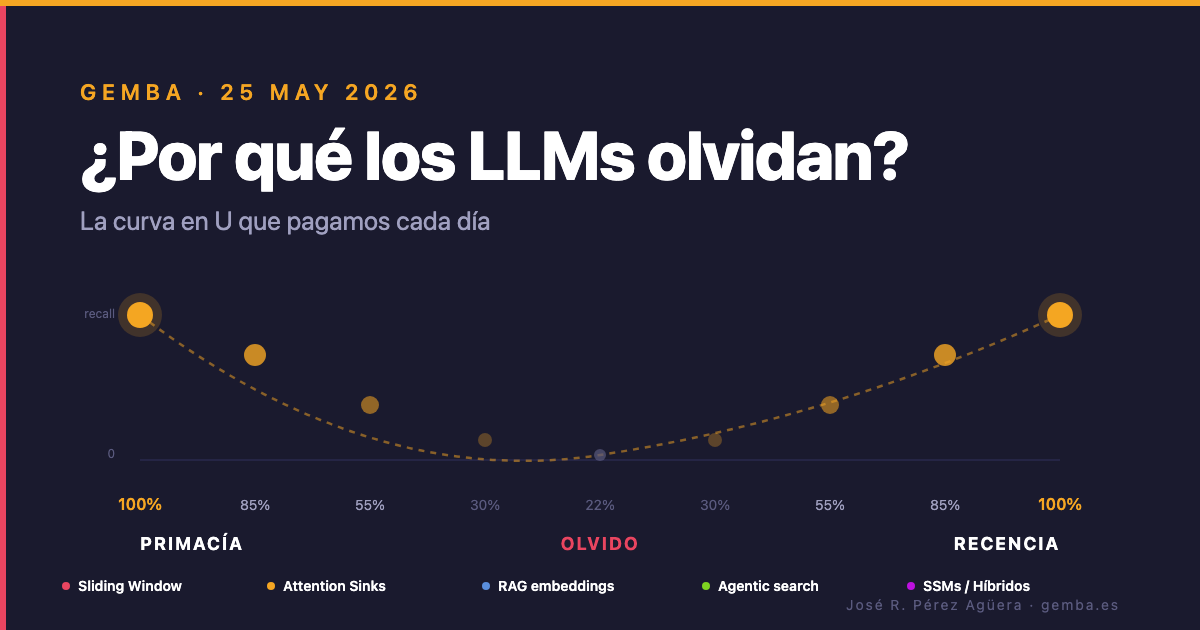
Lo que descubrieron es la curva en U. Los modelos —todos— recuperan mejor lo que está al principio o al final del contexto y peor lo que está en el medio. La caída entre la mejor posición y la peor es de quince a veinticinco puntos porcentuales. Para GPT-3.5-Turbo en su versión 16K, supera los veinte. No es ruido. Es un patrón sistemático, replicable, y aparece en arquitecturas, tamaños y proveedores distintos.
Pongamos a Murdock y a Liu en la misma tabla, separados por sesenta y cuatro años:
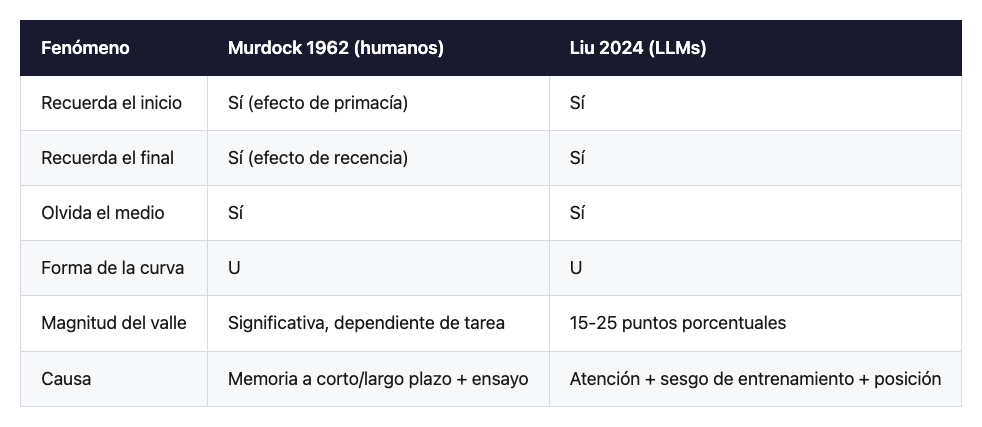
No es una coincidencia poética. Es una propiedad estructural de los sistemas con atención limitada, biológicos o de silicio. Cuando una operación cuesta n², el sistema aprende a no mirarlo todo. Y la heurística que emerge, casualmente, prioriza los extremos. Sea porque al principio del contexto suele ir lo importante (el system prompt, la pregunta original), sea porque al final está lo más reciente (el último turno del usuario, el detalle preciso), los modelos se vuelven especialistas en los bordes y amateurs en el centro.
La consecuencia práctica es brutal y sorprende a casi todos los equipos que la oyen por primera vez. Si metes un PDF de cien páginas a Claude y le preguntas algo de la página cincuenta, las probabilidades de que conteste bien caen entre 15 y 25 puntos porcentuales respecto a la misma pregunta sobre la página cinco o la noventa y cinco — esos son los órdenes de magnitud que midió Liu en los diez modelos de su experimento. No porque el modelo sea perezoso. No porque haya un bug. Porque ese token, sencillamente, está en el peor sitio posible.
Y hay algo aún más inquietante. Hsieh y un equipo de NVIDIA (RULER, presentado en 2024 en COLM —la Conference on Language Modeling, una de las nuevas conferencias específicas de modelos de lenguaje) extendieron el experimento de Liu con un benchmark más completo y midieron lo que llaman context efectivo: el tamaño real al que el modelo funciona bien, no el que aparece en la ficha técnica. El resultado es brutal: la mayoría de los modelos —comerciales y abiertos— tienen un context efectivo entre dos y ocho veces menor que la ventana que anuncian. Un modelo que vende 128k puede degradarse a partir de los 16k-32k. La ventana es marketing; el context efectivo es lo que importa.
Y la pregunta inmediata, claro, es: ¿se puede arreglar?
Cuatro mecanismos esquivan el problema. Y un quinto lo elimina
Spoiler de los cuatro primeros: ninguno lo elimina. Lo esquivan, cada uno con un compromiso distinto. Y lo esquivan con cuatro mecanismos conceptualmente independientes: truncar la atención (mirar solo a una ventana móvil), anclar ciertos tokens para que nunca se pierdan dentro de la ventana, externalizar el conocimiento preindexado fuera de la ventana, y navegar el entorno bajo demanda en lugar de cargarlo.
El quinto es más radical: salir del transformer entero. Cambiar la arquitectura por otra que no tenga atención cuadrática. Es lo que prometen los SSMs y los modelos híbridos, y ya hay opciones comerciales en producción.
Entender los cinco es lo que separa a un equipo que diseña con LLMs en serio de uno que reza para que la próxima versión sea mágica.
Sliding Window Attention — truncar la atención
La idea más obvia: si mirar a todos los tokens cuesta demasiado, trunca la atención. Que cada token solo mire a los W tokens más recientes. El coste cae de O(n²) a O(n·W), que es lineal con n. Lo que se pierde son las dependencias a larga distancia.
Esta es la familia de Longformer (Beltagy, Peters y Cohan, 2020), una de las primeras propuestas serias del problema, y la que adoptó Mistral 7B (Jiang et al. 2023) como pieza central de su arquitectura. Mistral usa una ventana W de 4.096 tokens en cada capa. Como los transformers tienen muchas capas apiladas, lo que un token “ve” en capas profundas es más ancho que su ventana literal —porque cada capa intermedia ya ha mezclado información de un tramo distinto—. En la práctica, encadenando capas, el modelo accede a un contexto efectivo de hasta 131.072 tokens sin pagar el cuadrático.
El precio es claro: si lo importante para responder está más allá de la ventana acumulada, el modelo no lo verá. Bien para hojear un documento largo de un tirón. Mal para una conversación donde lo que importa se dijo hace mil turnos.
Attention Sinks — anclar tokens críticos
La segunda familia introduce un mecanismo distinto: anclar ciertos tokens para que nunca se pierdan, independientemente de cuánto crezca la conversación. Surgió como respuesta a un problema raro y persistente que sufría la sliding window pura: cuando los primeros tokens de la secuencia llegaban al borde de la ventana y desaparecían, los modelos empezaban a colapsar. Salidas incoherentes, perplejidad disparada. En 2023, Guangxuan Xiao y un equipo del MIT (con Yuandong Tian, Beidi Chen, Song Han y Mike Lewis) descubrieron por qué.
Los primeros tokens de la secuencia, da igual cuáles sean, acumulan una cantidad enorme de atención durante el entrenamiento. No porque su contenido sea más valioso —pueden ser tokens basura, espacios o —, sino porque la softmax obliga a que los pesos sumen uno y, cuando un token no encuentra a quién atender bien, “deposita” peso en cualquier sitio. Y los primeros tokens, por construcción, siempre están ahí. Se vuelven attention sinks: sumideros de atención.
Su propuesta —que llamaron StreamingLLM— es preservar los primeros K tokens del contexto siempre, además de la sliding window normal. Esos K son las anclas; la ventana es el corto plazo. Con esa combinación, mostraron que un modelo puede generar de forma estable hasta cuatro millones de tokens sin fine-tuning. Sin colapsar.
La evolución natural de esta idea llegó en 2025 con Native Sparse Attention (DeepSeek, Best Paper de ACL 2025 —la conferencia más importante del campo): en lugar de aplicar el ancla como parche post-hoc sobre un modelo ya entrenado, se entrena al modelo desde el principio con un patrón de atención dispersa que aprende qué tokens funcionan como anclas y cuáles no. DeepSeek V3.2 ya lo usa en producción. Pasamos de la atención dispersa como remiendo a la atención dispersa nativa.
El precio: hay que modificar el caching del modelo o, en el caso de Native Sparse Attention, entrenarlo desde cero con esa estructura. No es algo que se aplique transparentemente a cualquier checkpoint público que ya tengas.
RAG con embeddings — externalizar el conocimiento preindexado
La tercera familia es la que probablemente ya estás usando sin saberlo, y es estructuralmente distinta de las dos anteriores: en lugar de tocar el mecanismo de atención, externaliza el conocimiento. La ventana del modelo se mantiene pequeña; el grueso del corpus vive fuera, en una base de datos vectorial aparte, y solo se trae a la ventana lo que parece relevante para la pregunta actual. Eso es RAG (Retrieval-Augmented Generation).
Cursor es el ejemplo más visible en el ecosistema de desarrollo: indexa el repositorio con embeddings, los almacena en una base vectorial, y en cada consulta usa búsqueda por proximidad para traer los trozos relevantes. Es también la base de cualquier agente conversacional serio que tenga que trabajar sobre una base de conocimiento más grande que la ventana del modelo.
El precio: dependes del retriever. Si el retriever falla en encontrar el trozo relevante, el modelo no tiene la información y se la inventa con la confianza de quien sí la tiene. La calidad del producto se vuelve, en buena medida, la calidad del recuperador.
Agentic search — navegar el entorno bajo demanda
La cuarta familia es la más reciente y la más radical: no preindexar nada. En lugar de calcular embeddings de todo el conocimiento por anticipado, el modelo navega el entorno bajo demanda usando las mismas herramientas que un programador en una terminal: grep —el comando de Unix de toda la vida para buscar texto dentro de los ficheros—, lectura de ficheros concretos, listar directorios, seguir referencias entre archivos.
Es la estrategia de Claude Code cuando te ayuda a editar un repositorio grande. Anthropic la defiende explícitamente frente a RAG con embeddings: “Claude Code navega un repositorio como lo haría un ingeniero: recorre el sistema de ficheros, lee ficheros, usa grep para encontrar exactamente lo que necesita, y sigue referencias”. El argumento es práctico: los pipelines de embeddings no aguantan el ritmo de equipos activos y devuelven referencias obsoletas. Mejor que el modelo decida en cada turno qué leer, como haría un humano.
El precio: latencia añadida en cada turno (cada grep o lectura es un viaje a la ventana del modelo), y dependencia de que el modelo razone bien sobre dónde buscar. A cambio, gana frescura (no hay índice que se quede obsoleto) y precisión local (el modelo lee el código real, no un trozo embebido hace tres semanas).
Salir de la jaula — arquitecturas no-transformer
Hasta aquí, todo dentro del transformer. Pero hay un quinto camino, conceptualmente distinto de los cuatro anteriores: cambiar la arquitectura. Si el problema es la atención cuadrática, ¿por qué no usar un modelo que no la tenga?
La candidata más madura en 2026 son los SSMs (State Space Models, o modelos de espacio de estados). Mamba (Gu y Dao, 2023) y su sucesor Mamba-2 (2024) procesan secuencias en tiempo lineal con n, sin atención cuadrática. La memoria del modelo se mantiene en un estado oculto que se actualiza recurrentemente, como una red neuronal recurrente (RNN) moderna, pero con una calidad de aprendizaje que se acerca a la del transformer.
¿Funciona en producción? Sí, hay ya modelos comerciales que apuestan por esta vía. Jamba 1.5 (AI21 Labs, 2024) combina capas Transformer, capas Mamba y MoE (Mixture of Experts, una técnica que activa solo una fracción de los parámetros del modelo en cada paso para abaratar el cómputo). Tiene ventana de 256k tokens y un throughput (tokens generados por segundo) tres veces mayor que Mixtral. Mistral Codestral Mamba, Google RecurrentGemma e IBM Granite 4.0 son apuestas comerciales del mismo enfoque.
El precio: la atención cuadrática, aunque cara, captura dependencias largas con precisión casi quirúrgica. Los SSMs comprimen esas dependencias en su estado oculto, y todavía no igualan al transformer puro en algunas tareas de retrieval exacto. Por eso los híbridos llevan ventaja por ahora: combinan transformers (precisión) con SSMs (escala) y se quedan con lo mejor de los dos mundos.
La dirección está clara: el O(n²) ha dejado de ser la única opción.
Compactación — la pieza ortogonal
La compactación (compaction en las docs de Anthropic) no es una quinta familia: es una pieza que combina con cualquiera de las cuatro. Cuando el historial de conversación empieza a llenar la ventana, le pides al modelo que resuma los turnos antiguos y sustituyes el detalle por el resumen. Pierdes precisión sobre lo viejo, ganas espacio para lo nuevo.
Anthropic ha hecho la compactación explícita en Claude Code: existe un comando /compact manual y un auto-compact que se dispara cuando el contexto se acerca al 95% del límite. Es una decisión deliberada: mejor que tú o el sistema decidan qué se comprime, en lugar de dejar que el lost-in-the-middle haga la criba por sus propios mecanismos.
Los cinco, vistos juntos
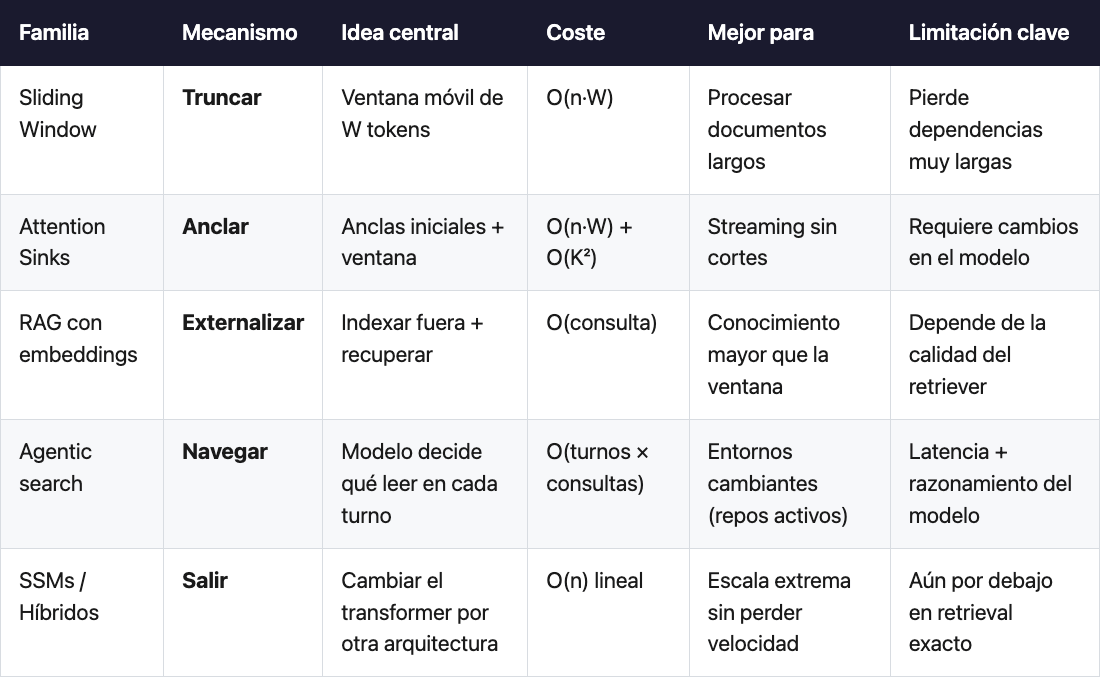
Los cuatro primeros esquivan el problema. El quinto lo elimina cambiando de arquitectura. Y la compactación es una pieza ortogonal que combina con cualquiera de ellos. La pregunta correcta para diseñar un producto con LLM no es “qué solución uso”, sino “qué combinación me conviene en cada parte de mi sistema”. Y para responder eso, conviene saber cuánto te está costando el olvido cuando no haces nada.
La factura del olvido
En el artículo anterior de Gemba expliqué que el coste de los tokens es multiplicador, no sumatorio: si tu modelo es caro y su tokenizer es malo para tu idioma, no pagas el sobrecoste una vez, lo pagas dos. Con el olvido pasa lo mismo, pero peor, porque la factura llega en tres formatos distintos y casi nadie la suma entera.
Primer formato: latencia. Generar el primer token de la respuesta requiere procesar todo el contexto. Si tu contexto crece linealmente, el tiempo hasta el primer token —Time To First Token, TTFT en la jerga— crece de forma más que lineal. Los proveedores aplican optimizaciones agresivas, pero las leyes de la física no se negocian: Claude Sonnet 4 con mil tokens de input tarda alrededor de un segundo en empezar a responder; con cien mil, entre dos y cinco (mediciones de Artificial Analysis). El crecimiento no es lineal, y la curva se empina a medida que te acercas al techo de la ventana. Multiplica eso por el número de turnos de un agente que reflexiona en bucle, y la latencia agregada empieza a ser dinero.
Segundo formato: repetición. Esta es la más invisible y la más cara. Cuando el modelo no recupera bien algo del medio de la ventana, el usuario lo nota y lo vuelve a meter. Le copia el bloque otra vez. Le repite la instrucción. Le recuerda el dato. Cada repetición son tokens duplicados que vuelves a pagar y que, encima, aumentan el tamaño del contexto y empeoran el problema en el siguiente turno. Es una espiral. Si llevas la cuenta de cuántas veces le has repetido la misma cosa a un LLM en una conversación de tarde, la respuesta es un número incómodo.
Tercer formato: alucinación. El más sutil y el más peligroso en producción. Cuando el modelo no encuentra información en su atención efectiva, no dice “no lo sé”. Rellena. Inventa con la prosodia de quien sabe. Y como el dato que necesitaba estaba en el contexto —solo que en el medio, donde la atención no lo procesa bien— el operador humano confía en que el modelo lo ha leído. La factura aquí ya no es de tokens. Es de decisiones tomadas con información incorrecta.
Pongámoslo en una tabla, que se ve mejor:
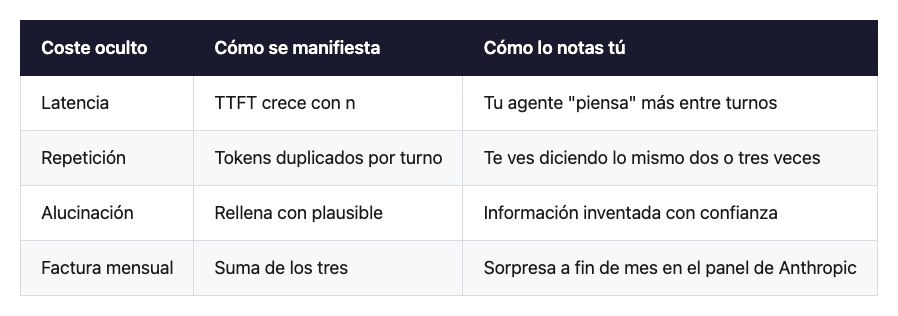
La parte cínica es que los tres costes se realimentan. Repites más → contexto más largo → latencia más alta + más medio donde olvidar → más alucinación → más repetición. No es una resta. Es un multiplicador, igual que con los tokens.
Y como pasa con los tokens, esta factura no aparece en una línea aparte de la factura de Anthropic o de OpenAI. Aparece como tiempo de tu equipo dándole vueltas a por qué Claude “se olvidó”, como horas de soporte explicando al cliente que sí, que la respuesta era inventada, y como una vaga sensación de que la IA “no termina de hacer lo que debería”. Eso es la factura del olvido. La pagas todos los meses, y casi nunca la mides.
¿Y se puede medir? Sí. Y es más fácil de lo que parece, una vez sabes mirar.
Lo que puedes hacer mañana por la mañana
Hasta aquí hemos visto la mecánica. La parte práctica es más corta porque, una vez entiendes que el olvido es estructural y no un capricho, las decisiones de diseño se ordenan solas. Estas son las seis que mejor amortizan el esfuerzo:
1) Pon lo crítico al principio y al final, nunca en el medio. Las instrucciones de sistema, los criterios de calidad, las restricciones inviolables, el formato de salida que esperas: todo eso va en zona de primacía. La pregunta concreta, los últimos datos, el matiz que el modelo no debe perder: zona de recencia. Lo que termine en el medio es lo que pondrás en riesgo. Diseña como diseñarías una landing: arriba lo importante, abajo el CTA, y haz que el medio sea pasaje, no producto.
2) No metas un PDF de cien páginas y reces. Si el contenido supera la mitad de la ventana, parte y recupera. Indexa el documento por secciones, monta un buscador sencillo —un retriever, en la jerga— y deja que el LLM solo vea los tres o cuatro trozos relevantes para la pregunta. La precisión sube y la factura baja a la vez. RAG funciona aunque sea con embeddings básicos —no hace falta exotismo para mejorar.
3) Repite las reglas críticas al principio Y al final. Si tu system prompt dice “responde solo en español y nunca inventes datos”, y la conversación es larga, el modelo verá la regla solo en zona de primacía. En conversaciones que pasen de varios miles de tokens, conviene reinyectar las restricciones críticas en el último turno antes de la respuesta. Es feo y funciona.
4) Compacta antes de que la ventana te compacte. No esperes a que el sistema decida qué tirar. Cada N turnos, pídele al modelo un resumen estructurado de la conversación hasta ese punto y sustituye los turnos antiguos por ese resumen. Pierdes detalle, ganas precisión sobre lo que queda. Mejor decidir tú qué se pierde a que lo decida una heurística que no controlas.
5) Subagentes para descargar contexto. Cuando una tarea requiere mucha investigación o exploración previa, hazla en un subagente con su propia ventana. El agente principal recibe solo el resultado final, no los miles de tokens intermedios. Es lo que hace Claude Code para no contaminar tu sesión con cada exploración del repo. La diferencia, en conversaciones largas, es brutal.
6) Mide tu propia curva en U. Los datos del paper de Liu son una referencia sólida, pero tu caso de uso — tu modelo, tu idioma, tu tipo de pregunta, tu tamaño de contexto — puede tener una curva distinta. No asumas. Mide. Bastan tres tamaños de contexto y cinco posiciones por cada uno para tener un mapa razonable de dónde está tu zona segura. A partir de ahí, diseñas con datos.
Diseñar para LLMs es, en buena medida, diseñar para sistemas con sesgo de primacía y recencia. Como diseñar páginas web para humanos. Lo curioso es que llevamos décadas haciendo esto último por buenas razones cognitivas, y ahora descubrimos que las mismas razones cognitivas, en silicio, exigen lo mismo. Murdock se hubiera reído.
Dos toolkits abiertos
Como hice con el artículo de tokens, he liberado dos repos en abierto (MIT) para que puedas experimentar y decidir, no solo leerme.
▪ Uno para entender — gemba-attention-from-scratch. Los tres mecanismos de atención —la versión vanilla del transformer, la sliding window de Mistral y Longformer, y los attention sinks de StreamingLLM— implementados desde cero en Python sin librerías externas. Y una demo viva que reproduce la curva en U usando GPT-2 small: mete una aguja en distintas posiciones de un texto largo y mide cuánto la recuerda el modelo. Para entender qué pasa por dentro.
▪ Otro para decidir — gemba-context-needle-runner. Una herramienta que mide el lost-in-the-middle en tu propio uso. Lanza el experimento de la aguja en el pajar contra OpenAI, Anthropic y modelos abiertos, varía el tamaño del contexto y la posición de la aguja, y te devuelve la curva de aciertos por posición. Para que dejes de adivinar dónde colapsa tu modelo y empieces a medirlo.
Uno para entender el mecanismo. El otro para saber cuánto te afecta a ti.
Sesenta y cuatro años después del experimento de Murdock, encontramos su curva en U dentro de unas máquinas hechas de matrices. Él la midió en sujetos humanos memorizando palabras. Nosotros la medimos en GPUs procesando tokens. Los mecanismos no tienen nada que ver. La forma sí. Y la consecuencia práctica también: lo que importa, va al principio o al final. El medio es zona muerta.
Los LLMs no olvidan. Pagan la factura cuadrática de la atención. Y mientras esa factura siga siendo n², el olvido no es un bug que vayan a arreglar en la próxima versión. Es una propiedad estructural, y diseñar productos con LLMs es, antes que cualquier otra cosa, diseñar alrededor de ese sesgo.
La pregunta práctica que te lleva todo esto: ¿en qué punto de tu contexto colocas lo crítico?
¿Habéis medido en tu equipo qué porcentaje del contexto que pasáis a Claude o ChatGPT influye realmente en la respuesta? Porque hasta que no lo midas, estás pagando una factura cuya magnitud no conoces.